ES6语法重点
在最近阅读了《深入理解ES6》这本书之后,发现ES6中有一些不为人所熟悉的部分却成为了提升开发效率的利器,所以将这些语法重点进行规整总结,分享输出给各位小伙伴.
块级作用域
临时死区
ES6中的块级作用域为了防止变量提升,产生了临时死区的方案,也就是说如果你在let、const定义块级作用域变量之前,直接使用此名称的变量,临时死区里面的逻辑就会报错,在执行同步代码度过临时死区之前,使用任何名称的变量都会报错,直到执行过临时死区之后,才会解封.
1 |
|
for循环中的块级作用域
ES6中for循环块级作用域中使用的let和const定义变量,和在普通的块级作用域中定义变量不同.for循环块级作用域中是循环的每一次都会声明赋值变量,不是对上次迭代变量的叠加或者累计,而是重新赋值声明,值等于上一次迭代变量加一.在for…in循环获取对象的属性集合项中,也是每一次迭代都会重新声明赋值属性.
1 | let arr = []; |
块级作用域最佳实践
ES6块级作用域最佳实践
尽量在业务开发中,全部使用const定义数据,只有认识到此数据是要进行计算的,就使用let定义数据.
原因
大部分的数据是不可变的,只是作为查询或者展示,而可变的用于前端计算赋值的数据在实际应用场景当中很少很少.
字符串
以码位而非字符来匹配字符
在没有引入Unicode之前,正则表达式使用以一个16位编码也就是两个码位来匹配一个字符,那时候2^16次方个字符在计算机的字符世界中是够用的,但是在引入Unicode之后,2^16次方个字符在诺大的字符集当中非常吃不消,所以正则表达式新增了u描述符,以一个码位也就是32位编码来匹配一个Unicode字符.至此,所有Unicode字符被分为两类,基本平面(BMP)以及辅助平面,BMP是在2^16次方哥字符之内的,而其余超出的则是辅助平面范围
1 | let str = '𠮷'; |
u描述符
1 | let str = '𠮷', |
如果u描述符要兼容老版本浏览器,需要使用try {} catch(err) {},并且使用构造调用,这样是最安全的
1 | try { |
各种新增的处理字符串的方法
includes,字符串中是否含有某字符或者某字符串
1 | let str = 'hello,world'; |
startsWith,字符串中是否以某字符或者某字符串开头
1 | let str = 'hello,world'; |
endsWith,字符串中是否以某字符或者某字符串结尾
1 | let str = 'hello,world'; |
repeat,将某字符或者字符串重复n次
1 | let str = 'pet'; |
y描述符,粘滞描述符
y粘滞描述符,是区别于g全局描述符,与正则表达式匹配的lastIndex有直接关系,其匹配必须从字符串的开头0下标开始,如果匹配,则从匹配结束的位置开始,再开始匹配,如果再次匹配不到,则回到字符串的开头0下标开始,多次匹配的规则在字符串中必须是连续的.
1 | let str = 'hello.hello.hello.hello.hello.', |
1 | let str = 'hello.hello.hello.hello.hello.', |
如果y粘滞描述符要兼容老版本浏览器,需要使用try {} catch(err) {},并且使用构造调用,这样是最安全的
1 | try { |
source、flags与sticky
source用于获取正则表达式的除了描述符以外的内容,flags则用于获取正则表达式的描述符,而sticky则是用于获取此正则表达式是否存在y粘滞描述符
1 | let reg_g = /hello./g, |
顺便说一下在没有flags来获取正则表达式的描述符时,一般会是这么去封装一个获取正则表达式描述符的方法
1 | function flags(reg) { |
模板标签
模板标签处理模板字符串的数据参数顺序以及源字符串的操作很便利,你只要写一个函数,并直接放在模板字符串前方,这样就可以直接模板字符串进行处理了,函数的第一个参数是一个数组,表示的是所有除了引入变量以外的字符片段的集合,而后面的参数则是按照引入变量的顺序从左至右的排开,你可以使用不定参数将其转化为数组,不论你怎么引入变量,字符片段的集合数组总是比不定参数转化的数组的长度多一,所以我们可以自己去写一个模板标签,用交织的形式去组合字符串的原顺序或是自定义顺序.
1 | let name = 'Gary', |
还有一种处理源字符串操作的模板标签,可以使源字符串不做转义.那就是String.raw
1 | let name = 'Gary'; |
它可以使换行、制表这些转义符不做转义,我们可以自己写一个和它一致的模板标签,每一个源字符片段都有一个raw的特有属性,其可以将其本身变为不可转义.
1 | let name = 'Gary'; |
函数
默认参数
默认参数使得传参更加简化、方便,只有传递的参数为undefined,就给予默认值,如果不为undefined,则进行赋值,类似于for循环let、const每次创建一个声明一样,默认参数也会在函数词法作用域的顶部使用let、const创建一个声明.
1 | function getPerson(name, age = 25, hobby = 'basketball') { |
甚至可以在非第一个默认参数上面去承接之前定义好的传参或者默认参数.
1 | function getNumber(first = 1, second = first) { |
但是默认参数也存在临时死区的,在没有把临时死区当中的变量释放出来之前,直接使用,会引起语法错误.
1 | function getNumber(first = second, second = 1) { |
也可使用函数返回值的形式作为默认参数.
1 | function getNumberOne() { |
不定参数
在ES6之前,对于不确定传参的数量的函数,我们基本上使用arguments对象来处理,但是不怎么方便,因为遇到很多情况是,我既有前几个确定的参数,又有后面不确定的参数,所以这时候的处理就需要跳过前几个确定的参数,比如UnderScore.js的pick方法,我们可以来模拟一下.
1 | function pick(obj) { |
在ES6中,为了使这种传参更加方便,引入了不定参数,我们无需对不确定的参数进行特殊处理,还是拿UnderScore.js的pick方法来模拟.
1 | function pick(obj, ...args) { |
不定参数必须以函数参数的最后位置出现,如果后方位置还有参数,则会报错
1 | function pick(obj, ...args, 'age') { |
展开运算符
在ES6之前,有一些内置函数和对象比如说Math.max不支持以数组传入参数,只能一个一个的传入,所以我们这时候就需要使用apply的形式,直接传入数组,然后转化为参数.
1 | let value = 100, |
在ES6推出了展开运算符之后,这种情况发生了改变,我们不需要使用apply的这种形式进行显式绑定.
1 | let value_arr = [0, 99 ,-10, 100, 1000, 2000, 200, 1]; |
有了展开运算符和不定参数的支持,在函数传参方面大为改观,我们现在可以使用这两种新形势进行配合写一个bind显式绑定方法.
1 | if(!Function.prototype.bind) { |
new.target
函数在普通调用和构造调用时,所使用的内置函数是不同的,普通调用使用的是[[Call]]内置函数,而构造调用使用的是[[Constructor]],而在一些必须使用构造调用的函数的判断就成了问题.在ES6之前是这样判断的
1 | function Person (name, age) { |
但是这样还是会有漏洞的,我们可以使用硬绑定,将Person硬绑定至构造调用出来的引用对象上面.
1 | function Person (name, age) { |
所以ES6推出了new.target,此对象总是指向构造调用函数本身的,也就是说使用[[Constructor]]去调用才会有此对象,如果使用[[Call]]去调用就不会有此对象也就等于undefined
1 | function Person (name, age) { |
块级函数
ES6中,因为有了块级作用域,所以对函数的声明限制在严格模式下做了强控,由此有了块级函数,只能在此块级作用域中可访问并调用到此函数,全局并不能访问到并调用
1 |
|
但是如果不是在严格模式下,不仅在此块级作用域中可访问并调用到此函数,全局依然可以访问并调用
1 | if (true) { |
name
说到name,就不得不说它被开创的原因,它本来是为了追溯堆栈信息而生,就是当出现某些错误的时候,比如TypeError、ReferenceError和SyntaxError时,引擎就会根据此函数的name查找所在函数的发生错误的位置,一层层寻找下去,形成函数调用时追溯错误信息的堆栈.而name就成了函数的名称,length就成了函数参数的个数.
1 | function person(name, age) { |
不同方式生成的函数的名称是不同的,比如说bind硬绑定,它所返回的函数的名称就是”bound [[函数真实名称]]”,而使用Function构造出来的函数的名称则是”anonymous”.
1 | function person(name, age) { |
1 | const person = new Function(); |
箭头函数
ES6中最让人感兴趣之一,也是变化最大之一的改动就是箭头函数了.特点在于它的方便和简化,它废弃了传统JS函数中的一些复杂而又让人费解的特性,其实际多应用在回调函数、Promise处理异步问题的结构中.
特性:
- 不可使用new绑定构造调用,就是说箭头函数里就无[[Constructor]]内置属性
- 不可改变函数this的指向,this永远指向外层词法作用域
- 不可在函数内部使用arguments,也就是说arguments在箭头函数里面压根儿不存在
- 不可在函数内部使用super,既然不能new绑定构造调用,那肯定也不能使用继承了,更不能使用super
不可使用new.target,既然不能new绑定构造调用,那肯定也用不了new.target,箭头函数里就无[[Constructor]]内置属性,而new.target又与[[Constructor]]内置属性相关
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15let name = 'Simon';
const obj = {
name: 'Gary',
getName: () => {
console.log(this.name);
}
};
const simon = {
name: 'Simon'
};
console.log(obj.getName());
console.log(obj.getName.call(simon));
//在这里打印
//undefined
//undefined1
2
3
4
5
6
7const Person = (name, age) => {
this.name = name;
this.age = age;
};
const aaron = new Person('aaron', 25);
//在这里会报类型错误
//Uncaught TypeError: Person is not a constructor
1 | const Person = name => { |
1 | const Person = name => { |
尾调用优化
其实尾调用优化的定义非常简单,目标也很清楚,就是一句话:循环利用某一堆栈,让我们先看一张图
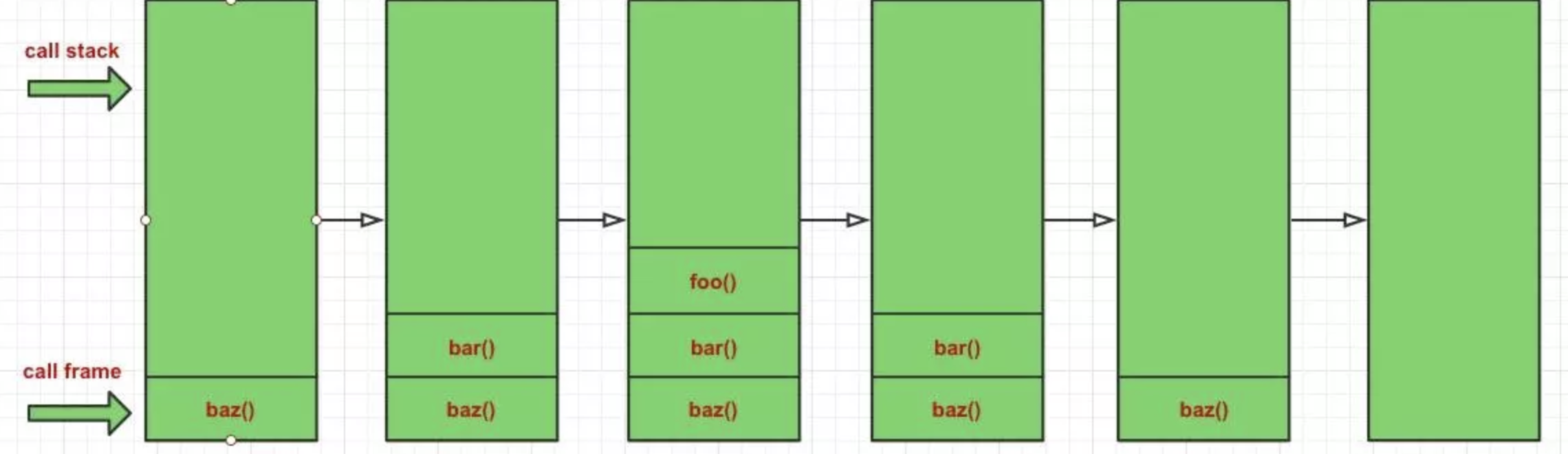
1 | function baz() { |
上述代码和图全面阐述了非尾调用时,函数堆栈执行的情形,当baz函数执行时,会将此函数推到内存的,但是baz函数不会因为执行调用而被销毁,因为内部还存在bar函数,等待bar函数执行完毕之后,baz才会从堆栈栈底销毁,而bar函数的执行,又会产生推到内存栈底的函数,以此类baz -> bar关系推bar -> foo是一样的,堆栈随着内部函数的调用不断累积,且不能第一时间被销毁,必须等待内部的堆栈调用完全销毁才能轮到自己.这种不可复用的堆栈使用,ES6给出了优化功能,那就是尾调用.
尾调用的条件
- 内部函数的调用必须在外层函数结构体的最后一行执行,并且进行返回.
- 不可在内部函数结构体中,使用任何外层函数结构体中的变量、方法,也就是说不能存在闭包或者词法作用域链等行为.
内部函数的调用必须在外层函数结构体的最后一行不可进行显式计算返回.
让我们举一个非尾调用优化的例子,来个阶乘吧
1
2
3
4
5
6
7
8
9
10function factorial(n) {
if(n <= 1) {
return 1;
} else {
return n * factorial(n - 1);
}
}
factorial(5);
//在这里打印:
//120再举一个阶乘尾调用优化的例子
1
2
3
4
5
6
7
8
9
10function factorial(n, total = 1) {
if(n <= 1) {
return total;
} else {
return factorial(n - 1, total * n);
}
}
factorial(5);
//在这里打印:
//120这就是尾调用优化,符合一开始我所说的是三个条件,递归调用函数是在函数结构体的最后一行,且并没有进行显式计算,不存在闭包和函数作用域链使用任何外层函数结构体中的变量、方法的情况.